OpenAI's New Image Model Thinks Before It Draws
gpt-image-2 shipped yesterday. Native reasoning. 8 coherent images per request. Legible text at 2K. And somewhere in a dashboard, Nano Banana 2 just lost its Arena top spot by 242 points.

OpenAI shipped ChatGPT Images 2.0 yesterday. New model ID: gpt-image-2. Free inside ChatGPT. Live on the API for anyone who's verified their org.
It's their first image model with native reasoning. The model thinks about the prompt before painting pixels, verifies its own output, and can hold a single creative brief across up to eight coherent images in one request.
I upgraded our blog image generator to it this morning. Here's what actually changed — with a few images from the new model sprinkled in so you can judge for yourself.
The one thing that matters: reasoning
Every image model before this one was a one-shot diffusion process. Send a prompt, it draws once. If the hands are wrong or the text is garbled, send another prompt, it draws again. No thinking step. No verification step. No "wait, does this actually say what the user asked for?"
gpt-image-2 has a reasoning step. OpenAI calls it Thinking mode (opt-in for Plus/Pro; Instant mode is default and still uses reasoning, just less of it). The model plans the composition, drafts, checks its work, and iterates internally before emitting the final image.
This is why three things that have been broken since DALL·E 2 finally work:
- Small text stays legible — UI screenshots, infographics, slide decks, app mockups, product labels
- Non-Latin scripts render correctly — Japanese, Korean, Chinese, Hindi, Bengali, Arabic all usable
- Characters stay consistent across a batch — generate 8 panels, same face, same outfit, same proportions
It's not magic. It's a reasoning loop bolted onto a diffusion model. But the downstream effect is that the category moved from "art toy" to "production asset engine" in one release.
What you can actually build now
Three capabilities I tested this morning, each rendered by gpt-image-2, each impossible on the previous generation.

Multilingual dense text. This used to be the canonical failure case for image models. Five scripts in one image, all crisp. I asked for a movie-style poster; gpt-image-2 held the layout, rendered each script at the correct proportions, and kept the atmosphere cohesive. The implications for global marketing assets, localized UI mockups, and multilingual infographics are the real story here.




n=4, gpt-image-2. Four scenes, the same protagonist across all of them — same face, same cyan jacket, same proportions. Character consistency used to require ControlNet or LoRA training. Now it's a parameter.Character consistency across a batch. One prompt, n=4, four scenes — and the protagonist stays recognizable across every panel. Same face, same outfit, same proportions. This used to require reference images, ControlNet, or hand-trained LoRAs. Now it's a single API call. For storyboards, explainer comics, ad creative, product photography across a campaign — this is what "production asset engine" looks like.
2K infographics that actually read. At 2560×1440, small text finally survives. Before this, you had to generate at low res and upscale — and upscalers hallucinate labels. Here the labels are the labels. For any information-dense asset (dashboard, data viz, explainer) this is the unlock.
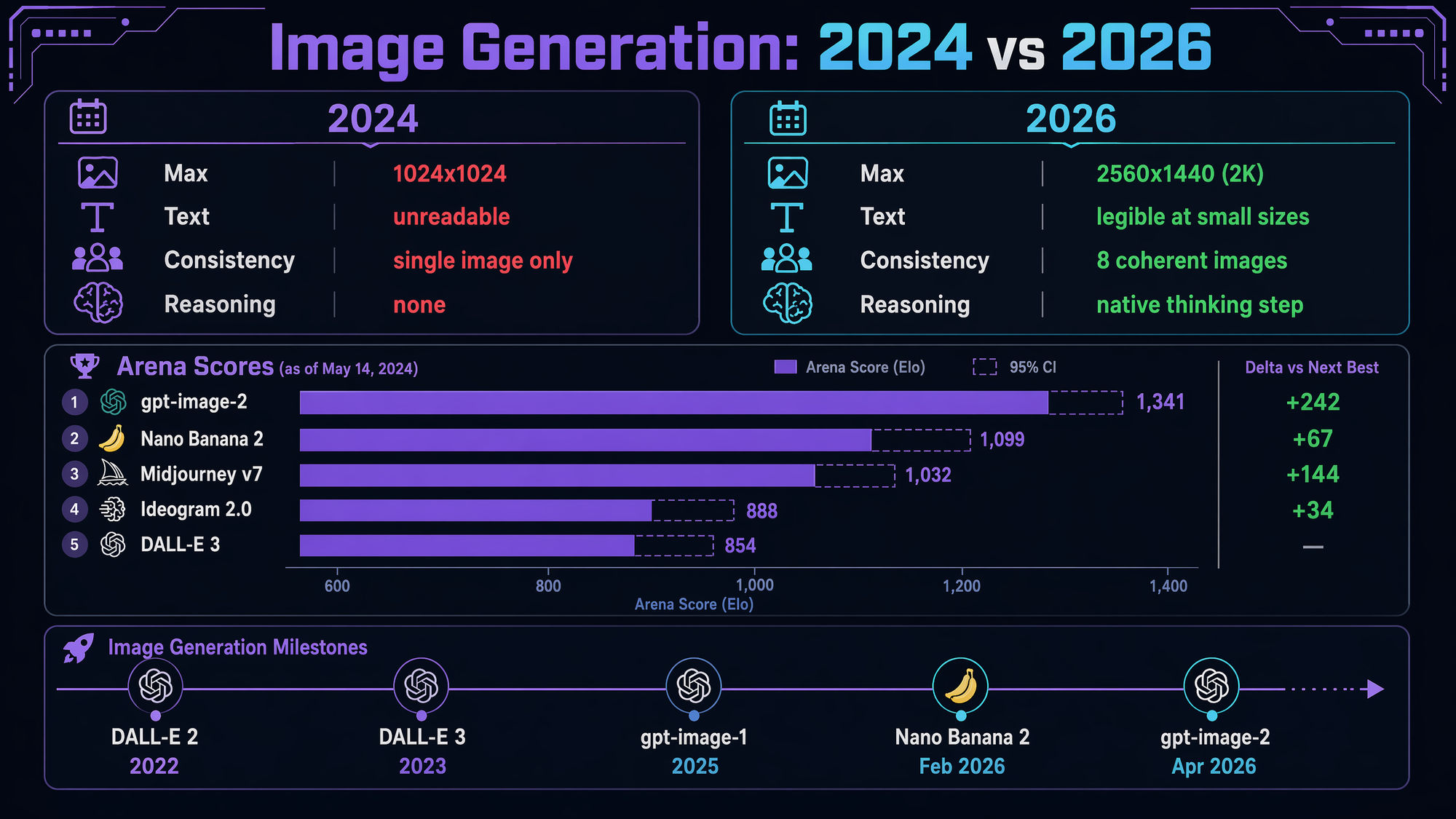
The Arena board
gpt-image-2 hit #1 on the Image Arena leaderboard within 12 hours of launch, with a +242 point lead — the largest single-model jump the board has ever recorded.
| Model | Launched | Arena rank |
|---|---|---|
| gpt-image-2 | Apr 21, 2026 | #1 (+242) |
| Nano Banana 2 (Gemini 3.1 Flash Image) | Feb 26, 2026 | #2 |
| Midjourney v7 | Jan 2026 | #3 |
| gpt-image-1.5 | Nov 2025 | #5 |
The Nano Banana context
If you've been out of the image-gen weeds: Nano Banana is Google DeepMind's image model line — a codename that somehow became the product's actual public identity. Nano Banana 2 (official name: Gemini 3.1 Flash Image) launched eight weeks ago and reset the whole category. It combined Imagen quality with Gemini Flash speed, added web-grounded knowledge for current logos and references, and shipped at roughly half the API price of comparable models. It instantly took #1 on Arena and became the default image engine across Gemini, Search AI Mode, Lens, Ads, and Flow.
gpt-image-2 is OpenAI's direct answer. Eight weeks of catch-up, then they leapfrogged with native reasoning. This is the pace the frontier runs at now — one major capability jump per model per quarter, alternating between the two labs.
The upside for the rest of us: the bar for "production-quality image generation" is rising fast, and all of it is API-accessible.
For builders: API migration
If you're already on gpt-image-1 or gpt-image-1.5 via the API, migration is a one-line change. Same endpoint (images.generate). Same core params. Swap the model ID.
model: "gpt-image-2"New things worth knowing:
n=1..8— batch generation with character/object consistency across the whole batch (was single-image only on 1.5)size: "2560x1440"— 2K output tier (priced higher than 1024/1536 tiers)- Instant vs Thinking — Instant is the default (still reasons, just faster). Thinking adds 15–30s latency and is gated to paid tiers.
- Web grounding — December 2025 knowledge cutoff, so current logos and recent cultural references render correctly without you describing them from scratch
One gotcha: your OpenAI org must be verified (government ID + selfie at platform.openai.com/settings/organization/general) before gpt-image-2 unlocks. Propagation takes up to 15 minutes after verification. Every future OpenAI frontier model will be gated on the same check — one-time hassle.
DALL·E 2 and DALL·E 3 retire May 12, 2026 — three weeks from now. gpt-image-1 and 1.5 remain live with no announced EOL, but they're obviously next in line for deprecation. Migrate when you get a chance.
Closing
Image generation stopped being about "make art" roughly eight weeks ago. It's now about "make slides, make app mockups, make infographics, make storyboards, make product photography with consistent branding across a campaign."
You can generate one featured image for a blog post. Or you can generate eight coherent panels for a product launch, a 2K infographic for a data-heavy deep-dive, a multilingual marketing asset for a global release — one API call, consistent outputs, text that actually reads.
Old workflow: prompt → generate → regenerate → touch up in Photoshop → ship.
New workflow: prompt → ship.
That's the actual difference.
Related reading
- Opus 4.7 Dropped. Here's What Actually Matters
- The Cockpit: One Command Center, Many Repos
- Claude Code: The Great Unlock



