The Architect's Protocol
A systems blueprint for AI-native engineering — how structured data, markdown knowledge bases, and Claude Code turn one engineer into an engineering department.

There is a moment in every engineer's career when the tools stop being tools and start being partners. When the terminal isn't just executing commands but orchestrating entire systems alongside you. When you stop writing code and start conducting it. That moment happened to me, and it fundamentally rewired how I build software.
This isn't another "AI is cool" post. This is a systems architecture document — a technical blueprint for how I actually work across different software projects every day. It's a protocol that turns one engineer into something closer to an engineering department. And the secret isn't the AI. It's the data.
The Command Center
Three screens. Not for vanity — for cognitive separation.
The left monitor runs iTerm2 in fullscreen. Multiple tabs, each one a Claude Code session connected to a different project. This is the cockpit. Every tab is a live collaboration with an AI that has full context on the codebase it's operating in — file structure, conventions, dependencies, business logic, history. I run Claude Code with a Max subscription at maximum effort, because when you're asking an AI to make architectural decisions across a complex microservice platform, you don't want it thinking on economy mode.
The center monitor runs Sublime Text. Not an IDE — a drafting surface. I keep a temporary markdown file on the Desktop where I compose prompts before sending them to Claude. This sounds trivial. It isn't. The difference between a productive AI session and a wasted one is the quality of the instruction. Writing prompts in a dedicated editor forces precision. You edit. You restructure. You think about what the AI needs to know before you hit enter.
The right monitor holds reference material. Documentation, API specs, architecture diagrams, the Slack thread I'm pulling context from.
This isn't ergonomic advice. It's a protocol for cognitive load management — execution on the left, composition in the center, reference on the right. Three cognitive modes, physically separated so they don't contaminate each other.
The First Principle: Data Quality Is Everything
Every framework, every methodology, every "10x developer" trick eventually reduces to one axiom: the quality of your output is bounded by the quality of your input. This is true for compilers, true for neural networks, and devastatingly true for working with large language models.
Most engineers using AI treat it like a search engine with attitude. Vague prompts, vague answers. Stack trace dumps and crossed fingers. "Refactor this" with no context on what this is, what it connects to, or why it exists. Then they complain that AI isn't useful for "real work."
The problem was never the AI. Garbage in, garbage out didn't stop being true just because the processor got smarter. An LLM operating on ambiguous, fragmented context will produce ambiguous, fragmented output. Every single time.
So I built a system that ensures the AI always has access to the highest-quality, most structured, most current data I can give it. Not through complex tooling. Not through expensive infrastructure. Through markdown files on Git.
The Knowledge Architecture
Every project I work on follows the same structural pattern. It doesn't matter if it's a large-scale enterprise platform or a personal blog managed through API automation. The architecture is identical:
CLAUDE.md sits at the project root. This is the instruction set — it tells Claude Code how to operate within this specific project. Conventions, rules, API patterns, things to never do, things to always do. Depending on the project's complexity, this file ranges from 50 to 300 lines. It's the difference between an AI that knows your codebase and an AI that knows your codebase and how you want it to behave inside it.
docs/ctx.md is the crown jewel. This is the knowledge base — a single markdown file that serves as the project's internal database. Everything the AI (or a human) needs to understand the full state of the project lives here. Architecture decisions and the reasoning behind them. API schemas. Business logic. Team agreements. Deployment procedures. Historical context about why things are the way they are.
These files range from a few hundred lines on a focused project to over 3,000 lines on complex enterprise platforms. The larger ones are organized into numbered parts with their own table of contents. They read like technical manuals because that's exactly what they are.
docs/*.md supplements the core with research documents — deep dives on specific subsystems, spike investigations, architectural proposals. Not every project needs them, but the ones that do typically have three to five of these files.
scripts/ contains automation. API helpers, report generators, image generation pipelines, data migration tools — whatever the project needs to reduce manual overhead to zero.
.env holds credentials. Git-ignored, always. Never in code, never in docs.
That's the entire system. Markdown files. Git. A folder structure any junior developer could understand in thirty seconds. The power isn't in the sophistication of the tooling — it's in the discipline of the data.
The Ingestion Layer
A knowledge base is only as valuable as the information flowing into it. My system ingests data from every source that produces signal:
- Emails — client communications, requirement changes buried in reply chains, technical decisions made in threads that never reach official documentation
- Slack messages — architecture discussions, incident responses, informal decisions that shape the codebase but never get written down
- Meeting transcripts — every meeting gets transcribed and processed. Every decision, every commitment, every "let's revisit this later" gets captured. Nothing said in a meeting should ever be lost
- Documents — PRDs, design specs, compliance requirements, onboarding guides, SOWs
- API connections — live data from project management tools, CI/CD pipelines, monitoring dashboards
- MCP servers — Model Context Protocol integrations that give Claude direct access to external systems and structured data sources
- Images and scans — whiteboard photos, architecture diagrams, scanned documents, screenshots
- Web pages — reference documentation, competitor analysis, vendor APIs, relevant research
None of these sources are valuable in isolation. A raw meeting transcript is noise. A Slack thread is chaos. An email chain is archaeology. The value is created when this raw material gets processed, structured, and integrated into the knowledge base — distilled into something the system can reason about.
The Continuous Refinement Loop
This is where the system becomes more than the sum of its parts. The workflow isn't linear — it's a continuous feedback loop:
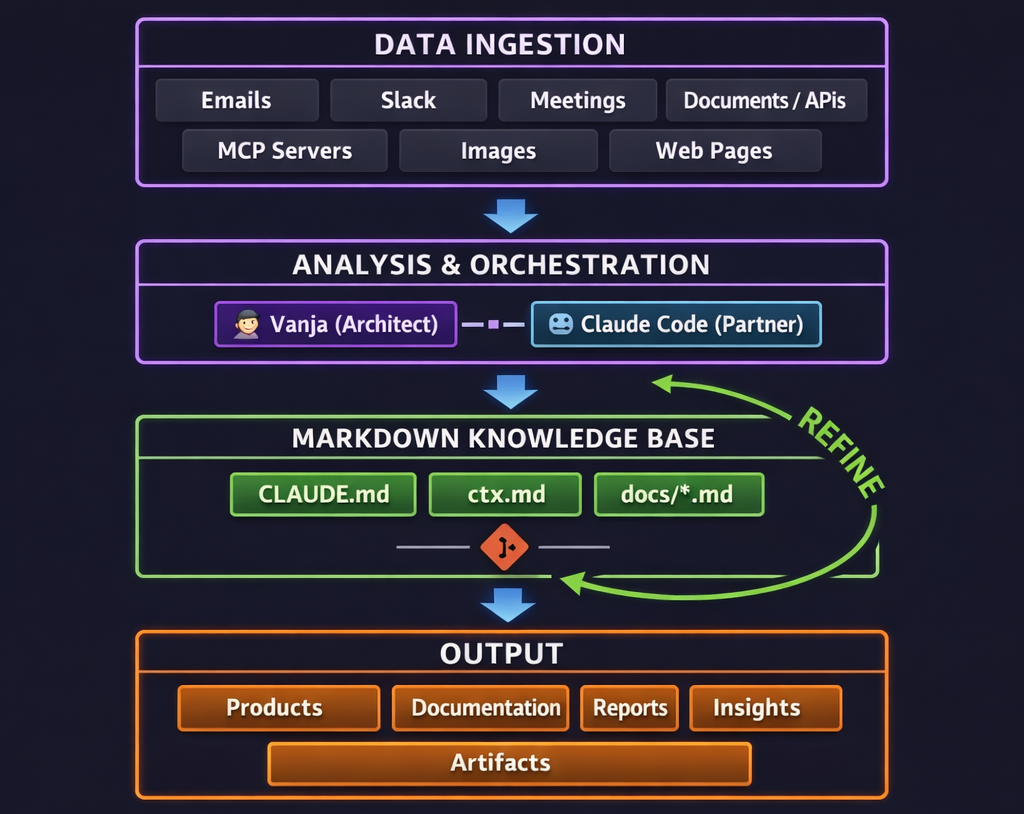
Ingest — raw data enters the system from any source. An email with a new requirement. A meeting where the team changed direction. A Slack message revealing a production issue nobody documented.
Analyze — this is the partnership. Vanja and Claude process the raw data together. What does this mean for the project? Does it change the architecture? Does it invalidate a previous decision? What needs to be updated, and where?
Store — the processed information gets written into the knowledge base as structured markdown. Every decision includes the why. Every change is tracked. The knowledge base doesn't just record what happened — it records the reasoning, the constraints, the tradeoffs.
Refine — here's the key. The updated knowledge base feeds directly back into the analysis step. Next time Claude opens this project, it has the new context immediately. The system learns by accumulation. Nothing is ever lost. Context compounds over time like interest.
Output — products ship, documentation gets written, reports get generated, insights emerge that wouldn't have been visible without the accumulated context. And even the outputs feed back — a shipped feature updates the knowledge base with its final implementation details, closing the loop.
This cycle runs continuously. Not on a schedule. Not in sprints. In real time, with every interaction, every meeting, every commit.
Operating at Scale
I've applied this system across the full spectrum of software engineering complexity — from large-scale enterprise platforms with dozens of microservices to lean API migrations to the very blog you're reading right now.
On complex enterprise projects, the knowledge base grows deep. Thousands of lines covering architecture decisions, authentication flows, regulatory constraints, and the rationale behind API design choices made months ago. Supplementary research documents capture deep dives on specific subsystems. Confidentiality rules get baked directly into CLAUDE.md — the instruction set doesn't just tell the AI what to do, it tells it what to protect.
On focused migrations and refactors, the knowledge base stays lean but surgically precise. Phase-based work logs tracking every decision and why it was made. When you're migrating APIs on a live platform, you need to know exactly why you chose approach A over approach B six weeks ago.
On product-driven work, the knowledge base captures business context alongside technical architecture. PERT estimation with dual tracks: one for AI-assisted development, one for traditional timelines. Because when you're estimating work in this paradigm, you need two sets of numbers — and the gap between them keeps growing.
Even a personal blog becomes a sophisticated system when you apply the same discipline. This blog has over 100 published posts managed entirely through API automation — automated SEO optimization, internal cross-linking, AI image generation for feature images, a ten-step mandatory publishing workflow enforced by CLAUDE.md.
The point isn't the type of project. It's that the same architecture works at every scale. A 3,000-line knowledge base and a 400-line one follow the exact same structural pattern. The protocol scales because markdown scales. Git scales. Structured data scales.
What the System Produces
Output isn't just code. That's the reductive view of engineering that this paradigm renders obsolete. The system produces:
Products — features, services, APIs, entire applications. Built faster and with fewer defects because the AI always has full context. No more "I forgot about that edge case" or "I didn't know we changed that API last month." The knowledge base remembers everything.
Documentation — not as an afterthought, but as a natural byproduct. When your knowledge base is always current, documentation writes itself. The ctx.md is the documentation. It's always up to date because keeping it up to date is part of the loop, not a separate chore.
Reports and analysis — sprint summaries, architecture assessments, migration progress reports, PERT estimates. When all project data lives in structured markdown, generating a report is a query — not a two-day research project.
Insights — the unexpected output. When an AI has access to thousands of lines of accumulated project knowledge, it sees patterns you missed. Connections between decisions made months apart. Implications of recent changes on distant parts of the system. The knowledge base becomes a thinking partner, not just a reference document.
Artifacts — estimation documents, technical proposals, onboarding materials, meeting preparation briefs. High-leverage work that traditionally takes hours of context-gathering, reduced to minutes because the context is already gathered, structured, and version-controlled.
The Protocol
Twenty years of software engineering taught me that the best systems aren't the most complex. They're the ones with the clearest abstractions and the most disciplined data flows. This system is, at its core, embarrassingly simple:
- Markdown files that both humans and AI can read and write
- Git for version control, because nothing should ever be lost
- A consistent folder structure replicated across every project
- A continuous loop of ingestion, analysis, storage, and refinement
- An AI partner operating at maximum capability with maximum context
No proprietary platforms. No vendor lock-in. No complex infrastructure. If Claude disappeared tomorrow, the knowledge bases would still be there — readable, portable, valuable. Every line of every ctx.md is plain text under version control. If I switched to a different AI partner, the onboarding would take minutes: point it at the markdown files and go.
This is what I mean by the architect's protocol. Not a tool. Not a framework. A discipline — for treating data as the most valuable asset in your engineering practice, for structuring that data so it compounds over time, and for collaborating with AI not as a code generator but as a genuine intellectual partner.
We're in the early chapters. The models improve every few months. Context windows expand. Agent capabilities compound. The protocol stays the same because it was never about any specific AI — it's about the data architecture that makes any AI maximally effective.
The engineers who will thrive in this era aren't the ones who type the fastest or memorize the most APIs. They're the ones who build the best knowledge systems. The ones who understand that in an age of increasingly powerful AI, the bottleneck is — and always has been — the quality of the data you feed into it.
Initialize your system. Build your knowledge base. Start the loop.
The protocol is running.
Related Reading
- From AI Skeptic to AI Architect
- The AI Native Software Engineer
- PRD System for Claude Code
- Claude Code: GUI vs Terminal
Related Reading
- The Third Pass — Multi-agent engineering: Claude Code builds, Codex reviews, human orchestrates.
- The Last Interface
- Claude Code Remote Control: Your AI Coding Agent in Your Pocket
- The Knowledge Equation — Why domain knowledge is the real AI differentiator
- The Context Wall — When your knowledge base outgrows a single file
- The Knowledge Base That Builds Itself — Let your AI maintain your knowledge base
- The Cockpit — Where to store your knowledge base across multiple repos



